Runpod AI云服务器 2026 最新深度评测:支持 4090、H100、Serverless 和 SSH 远程开发,对比 Vast 哪个更适合 AI 开发?
现在做 AI 绘画、部署大模型、训练 LoRA、搭建 ComfyUI,越来越多人开始接触 GPU 云服务器。而在众多平台中,Runpod 算是目前开发者使用最多的平台之一。很多人第一次接触 Runpod 时都会有各种问题:Runpod 是什么?和 Vast.ai 相比哪个好?支持 RTX 4090、5090、H100、A100 吗?能不能 SSH 登录、连接 VSCode、Cursor?有没有 Serverless API?适不适合跑 ComfyUI、Stable Diffusion、Flux、LLM、大模型训练?这篇文章会从实际使用角度,带大家全面了解 Runpod 的产品体系、GPU 类型、存储方式、计费模式以及适合哪些人使用,同时也会对比 Vast 的区别,帮助你找到适合自己的 AI 算力平台。无论你是独立开发者、AI 创业团队,还是需要部署推理 API、训练模型、搭建图像视频生成工作流,这篇文章都值得收藏。
Runpod 是一个面向 AI、机器学习和高性能计算的云计算平台。根据 Runpod 官网与官方文档,Runpod 的核心产品并不只是一种租 GPU,而是一整套 AI 基础设施,主要包括:
- Pods:适合需要直接控制容器、GPU、存储和运行环境的工作负载
- Serverless:适合按请求自动扩缩容的 AI 推理服务
- Public Endpoints:适合直接通过 API 调用现成模型
- Instant Clusters:适合多节点训练和大规模分布式推理
如果你是第一次接触 Runpod,可以先把它理解成一个专门为 AI 工作负载设计的平台:既可以像云服务器一样创建长期运行的 GPU 实例,也可以像 Serverless 平台一样按调用部署模型接口。
如果你搜索的是下面这些问题,这篇文章会集中回答:
- Runpod 是什么,适合哪些用户
- Runpod 有哪些 GPU,价格大概怎么计
- Runpod 和 Vast 有什么区别
- Runpod 适不适合部署 AI 推理、训练、ComfyUI 或 API
- Runpod 是否支持 SSH、VSCode、持久化存储和长期运行
从 SEO 和实际使用角度看,Runpod 最值得关注的不是单一一项功能,而是它把 Pods、Serverless、Public Endpoints、Instant Clusters 这些产品线整合到了一起,适合同一个项目从测试到上线逐步扩展。
Runpod 的核心产品线
Pods
Pods 是 Runpod 最基础、也是最常用的产品。官方将 Pods 定义为 专用 GPU 或 CPU 实例,适合以下场景:
- AI 开发与实验
- 模型训练与微调
- 长时间运行的推理服务
- 图像、视频、渲染等计算密集型任务
- 需要自定义容器和持久化工作空间的项目
Pods 的关键特点:
- 基于 Ubuntu Linux 容器环境
- 可自选 GPU、vCPU、内存、容器镜像、磁盘和网络配置
- 支持模板快速部署,也支持自定义镜像
- 支持 SSH、JupyterLab、API、Web 代理、VSCode/Cursor 连接
- 适合需要完整运行环境控制权的用户
Serverless
Runpod Serverless 是官方提供的按量计算平台,适合 AI 模型推理和自动扩缩容场景。官方文档强调,Serverless 的重点是:
- 不需要自己管理服务器
- 根据请求量自动扩缩容
- 空闲时不需要持续保留计算资源
- 按实际计算时间计费
Serverless 里的几个关键概念:
- Endpoint:外部访问入口
- Worker:真正执行代码的容器实例
- Handler Function:处理请求的业务函数
- Cold Start:无活跃 Worker 时首次拉起容器和加载模型的启动时间
如果你的目标是部署 AI API,而不是自己长期维护一台 Pod,那么 Serverless 往往更合适。
Public Endpoints
Public Endpoints 是 Runpod 提供的现成模型 API。官方文档的定位非常明确:
- 通过简单 API 调用现成模型
- 可在 Playground 中先测试,再生成示例代码
- 适合图像、视频、语音、文本等模型能力接入
- 按模型的实际使用量计费
如果你不想自己搭环境、不想维护容器,只想直接把 AI 能力接进应用,Public Endpoints 是最省事的入口。
Instant Clusters
Instant Clusters 是 Runpod 面向多节点训练和分布式推理的托管集群产品。官方文档提到的核心能力包括:
- 全托管多节点计算集群
- 单数据中心内高性能网络
- 自动配置静态 IP 和分布式训练所需环境变量
- 支持 Slurm、PyTorch、Axolotl 等用法
- 适合大模型训练、分布式微调、批量推理等场景
官方当前强调的网络能力是:
- 多数集群提供 3200 Gbps 集群内网络
- A100 集群最高可到 1600 Gbps
- 标准按需集群通常支持 2 到 8 个节点(16 到 64 张 GPU)
如果你的需求已经超出单机多卡,Instant Clusters 才是 Runpod 真正有差异化优势的地方之一。
Pods 的两种云类型
Runpod 官方将 Pods 分为两类:
Secure Cloud
官方描述为运行在 T3/T4 数据中心 的环境,更强调:
- 可靠性
- 安全性
- 企业和生产工作负载适配
如果你对稳定性、数据中心环境和生产可用性要求更高,通常优先看 Secure Cloud。
Community Cloud
官方描述为将经过审核的独立算力提供方接入平台的模式,特点是:
- 价格更有竞争力
- GPU 选择更灵活
- 更适合预算敏感或实验型工作负载
如果你主要看重成本,Community Cloud 往往会更有吸引力。
Runpod 和 Vast 对比
很多用户在选择 GPU 云平台时,实际搜索词往往是 Runpod vs Vast、Runpod 和 Vast 哪个更好、Runpod 还是 Vast 更适合 AI 绘画/推理/训练。如果你也是这个需求,可以先看下面这张简表。
| 对比项 | Runpod | Vast |
|---|---|---|
| 平台定位 | AI 基础设施平台,产品线更完整 | GPU 算力市场,偏 marketplace 模式 |
| 核心产品 | Pods、Serverless、Public Endpoints、Instant Clusters | 以 GPU 租赁和实例筛选为主 |
| 适合场景 | AI 开发、API 部署、推理、训练、分布式集群 | 预算优先、灵活找低价 GPU、短期任务 |
| 稳定性取向 | 更强调 Secure Cloud、Serverless、集群能力 | 更强调市场供给和价格弹性 |
| 上手方式 | 可选模板、Hub、Endpoint、Pod 多种路径 | 更偏直接租实例后自行使用 |
如果你更在意 产品完整度、Serverless、生产化推理和多节点能力,Runpod 通常更有吸引力;如果你更在意 极致性价比和 marketplace 弹性,很多用户也会继续关注 Vast。
如果你想看更完整的比较,可以继续阅读这篇对比文章:Runpod 和 Vast 详细对比
Runpod 支持哪些 GPU
根据 Runpod 官方 GPU types 参考页,当前平台支持的 GPU 类型覆盖面非常广,既有消费级显卡,也有数据中心卡和专业卡。
常见高端数据中心 GPU
- AMD Instinct MI300X OAM 192GB
- NVIDIA B200 180GB
- NVIDIA H200 SXM 141GB
- NVIDIA H100 SXM 80GB
- NVIDIA H100 PCIe 80GB
- NVIDIA H100 NVL 94GB
- NVIDIA A100 PCIe 80GB
- NVIDIA A100 SXM 80GB
常见专业卡与推理/训练卡
- NVIDIA L40 48GB
- NVIDIA L40S 48GB
- NVIDIA L4 24GB
- NVIDIA A40 48GB
- NVIDIA RTX 6000 Ada 48GB
- NVIDIA RTX A6000 48GB
- NVIDIA RTX A5000 24GB
- NVIDIA A30 24GB
常见消费级 GPU
- RTX 5090 32GB
- RTX 5080 16GB
- RTX 4090 24GB
- RTX 4080 / 4080 SUPER 16GB
- RTX 4070 Ti 12GB
- RTX 3090 / 3090 Ti 24GB
- RTX 3080 Ti / 3080
- RTX 3070
小结
Runpod 并不是只提供 H100、A100 这类贵卡,也覆盖大量 24GB、48GB、80GB、141GB 乃至更高显存的 GPU。对于不同预算和任务类型,选择空间非常大。
如何按场景选择 Pod
Runpod 官方在 Choose a Pod 文档中给出的核心思路,是先看自己的工作负载,再匹配 GPU、显存、存储和预算。
官方建议重点关注的几个维度
- GPU 架构是否兼容你的框架
- VRAM 是否足够
- CPU 和内存是否能支撑数据处理
- 存储是否需要持久化
- 是否可以接受 Spot 中断
- 是否需要长期稳定运行
关于显存的官方经验值
Runpod 官方文档给出了一条很实用的经验规则:
运行 LLM 时,可以先按每 10 亿参数约需要 2GB VRAM做粗略预估。
例如:
- 7B 模型,通常先从 14GB 左右显存级别开始估算
- 13B 模型,通常先从 26GB 左右显存级别开始估算
- 更大的模型还需要结合量化、上下文长度、批大小和框架开销进一步评估
按任务粗分
| 任务类型 | 更常见的选择方向 |
|---|---|
| 轻量推理、开发测试 | L4、RTX 3090、RTX 4090、RTX A5000 |
| 图像生成、ComfyUI、扩散模型 | RTX 4090、RTX A6000、L40S |
| 中大型 LLM 推理 | A100、H100、H200、L40S |
| 长时间训练与微调 | A100、H100、H200 |
| 多节点分布式训练 | Instant Clusters |
上表是按官方产品能力整理出的选型方向,实际还是要以你使用的框架、模型和控制台当下可用库存为准。
Runpod 的模板、镜像与部署方式
Pod Templates
Runpod 官方提供 Pod Templates,本质上是预配置的 Docker 部署模板。它的价值在于:
- 省去手动配环境的时间
- 降低镜像和依赖配置错误
- 让常见工作负载可以快速起跑
你可以通过模板快速拉起常见开发环境,也可以改成自己的容器镜像。
自定义容器
官方文档明确支持:
- Docker Hub
- GitHub Container Registry
- Amazon ECR
- 自己构建并发布的兼容镜像
如果你已经有成熟的 Docker 工作流,Runpod 的 Pods 会更适合你,而不是把它当传统 VPS 使用。
Runpod Hub
Runpod Hub 是官方的模型与 Worker 分发入口之一。官方文档中,Hub 主要承载两类使用方式:
- 从 Hub 快速部署 Serverless repo
- 选择现成能力进行测试、部署和二次开发
如果你更偏 AI 应用交付,而不是运维底层容器,Hub 会比从零搭环境更省时间。
存储方式怎么选
Runpod 官方把存储分得比较清楚,这一点和很多普通云服务器很不一样。
Container Disk
- 每个 Pod 都有
- 存放系统和临时文件
- Pod 停止后,临时内容会被清除
Volume Disk
- 属于 Pod 生命周期内的持久化磁盘
- 默认工作目录通常是
/workspace - Pod 停止后数据仍保留
- Pod 删除后,这部分数据会被清除
Network Volumes
这是 Runpod 官方单独强调的一种 独立于计算资源存在的持久化存储。它的特点是:
- 数据可独立于 Pod 或 Serverless Worker 存在
- 可在多个 Pod、Serverless Endpoint、Instant Cluster 之间复用
- 适合保存模型、数据集、共享文件和长期工作空间
- 底层使用高性能 NVMe SSD,通过高速网络访问
官方文档提到,Network Volumes 的典型传输速度通常在 200 到 400 MB/s,峰值可到 10 GB/s,但实际表现与机房和网络条件有关。
另外还有两个官方限制需要特别注意:
- Network Volumes 用在 Pods 时,目前只适用于 Secure Cloud
- 给 Pod 挂载 Network Volume 需要在部署时完成,不能对已经创建好的 Pod 事后追加挂载
使用建议
| 需求 | 更适合的存储 |
|---|---|
| 临时运行任务 | Container Disk |
| Pod 停止后仍要保留当前工作区 | Volume Disk |
| 删除 Pod 后仍要保留数据 | Network Volume |
| 多个 Pod/Endpoint 共享模型或数据集 | Network Volume |
如何连接和使用 Runpod Pod
根据官方文档,Pod 部署完成后常见连接方式包括:
- SSH:命令行远程管理
- Web Proxy:通过
https://[pod-id]-[port].proxy.runpod.net暴露 Web 服务 - API:程序化管理 Pod
- JupyterLab:浏览器内使用交互式开发环境
- VSCode / Cursor:像远程开发机一样直接连接
对于开发者来说,这意味着 Runpod 更像一套AI 远程工作站 + GPU 运行平台,而不只是一个简单的 GPU 租赁页面。
Runpod 适合哪些用户
1. AI 开发者
如果你要自己装框架、改环境、跑训练脚本、调模型,Pods 会比较合适。
2. 大模型推理与微调用户
如果你需要部署 vLLM、做模型推理、LoRA 微调或长时间实验,Runpod 的 GPU 选择和产品形态都比较完整。
3. 图像与视频生成用户
官方产品体系本身支持容器化部署,也支持通过 Public Endpoints 调用现成模型,因此适合:
- ComfyUI 类工作流
- 图像生成 API
- 视频生成 API
- 批量处理任务
4. AI 创业团队
如果你同时需要:
- 测试模型
- 部署 API
- 管理 Serverless 推理
- 后续扩到多节点训练
那么 Runpod 的产品线衔接会比单一 GPU 租赁平台更顺手。
5. 企业和大规模团队
如果你需要更明确的生产能力、Secure Cloud、Instant Clusters 或大额结算方式,Runpod 也有更偏企业化的入口。
Runpod 的主要优点
产品形态完整
不是只有 Pods。Runpod 把 Pods、Serverless、Public Endpoints、Instant Clusters、Hub、Network Volumes 都串起来了,适合从开发到上线逐步扩展。
GPU 选择范围大
官方 GPU 列表覆盖消费级卡、专业卡、数据中心卡以及更高端的新一代 GPU,选型空间非常大。
对开发者友好
支持 SSH、JupyterLab、Web Proxy、VSCode/Cursor、API、自定义镜像、模板部署,这些都很适合开发和实验场景。
适合 AI 场景而不是泛用云主机思路
从官方文档结构就能看出来,Runpod 是围绕 AI 工作流设计的,尤其适合:
- 模型推理
- 训练与微调
- 图像/视频生成
- 批处理任务
- 多节点训练
存储设计更灵活
Network Volumes 可以脱离计算实例长期存在,这对模型、数据集和工作空间管理非常实用。
使用 Runpod 前要注意的限制
这些内容都能在官方文档中找到,属于真正使用前需要知道的点。
Pods 不支持 Windows
Runpod 官方在 Pods 文档里明确写了:Pods 当前不支持 Windows。
如果你的业务强依赖 Windows 环境,Runpod 并不是合适选择。
Pods 不支持 Docker Compose
官方说明:Runpod 已经在底层帮你运行 Docker,因此用户不能在 Pod 里再自己起 Docker 实例,也不能直接使用 Docker Compose。
如果你的项目强依赖多容器编排,通常需要提前把需要的组件打进自定义镜像,或者调整架构。
Pods 不支持 UDP
官方文档明确指出 Pods 只支持 TCP 和 HTTP。如果你的应用依赖 UDP,需要先确认协议层能否改造。
Spot 实例会被中断
如果你选择 Spot,官方定义就是使用空闲算力资源,价格更低,但实例是 可中断 的。
适合:
- 容错型批处理
- 实验任务
- 可恢复训练
不适合:
- 关键生产任务
- 不能中断的在线服务
Runpod 不是云备份盘
官方在存储和计费文档中反复强调:Runpod 的存储是为运行任务服务的,并不是面向通用云备份设计的。如果余额不足导致存储被回收,官方不能帮助找回丢失的数据。
所以重要数据一定要定期备份到本地或独立存储服务。
计费方式
Pods 计费
根据官方 Pods / Pricing 页面,Pods 支持三种主要计费模式:
- On-Demand:按需使用,适合不允许中断的工作负载
- Savings Plan:预付承诺期,换取更低价格,适合长期稳定使用
- Spot:最低价,但资源可中断
官方定价页和定价文档目前强调的是:
- Pods 按量计费
- 无额外数据流入/流出费用
- 具体 GPU 价格以控制台与实时库存为准
另外,官方还提到:
- 你至少需要有相当于所选 Pod 1 小时运行费用 的余额,才能租用对应配置的 Pod
- 如果余额耗尽,Pod 可能会被自动停止,后续甚至可能被系统删除
Serverless 计费
Serverless 采用官方强调的 按秒计费 模式,并区分两类 Worker:
- Flex Workers:空闲时可缩到 0,更省钱
- Active Workers:始终在线,通常比 Flex 有 20% 到 30% 左右折扣,但会持续计费
这意味着:
- 流量波动大、请求不连续时,Flex 更适合
- 对延迟敏感、请求持续稳定时,Active 更适合
Public Endpoints 计费
Public Endpoints 按模型的具体使用单位计费,例如:
- 图像模型可按 每百万像素 计费
- 视频模型可按 视频时长 计费
- 文本模型可按 token 计费
- 语音模型可按 音频字符量或处理量 计费
官方文档的核心意思很明确:你为实际生成结果付费,而不是为底层基础设施付费。
存储计费
官方文档中和用户关系最密切的几个点如下:
- 运行中的 Pod,存储按月折算收费
- 停止后的 Pod,Volume Storage 的计费规则不同于运行中状态
- Network Volumes 当前官方标价为:
- 前 1TB:$0.07 / GB / 月
- 超过 1TB:$0.05 / GB / 月
如果你长期保留大量模型和数据集,Network Volume 的成本也要一起算进去。
支付方式
Runpod 官方文档列出的主要入金方式包括:
- 信用卡
- 加密货币
- Business Invoicing(适合较大金额,官方写的是超过 5000 美元)
另外,官方还有几个需要特别注意的规则:
- 充值后的 Runpod credits 不可提现
- 未使用余额 通常不支持退款,credits 也被官方定义为 non-refundable
- 新账号会有 spending limits,主要用于防止欺诈
如果你需要解决海外扣款、AI 平台订阅或绑定虚拟信用卡的问题,可以参考这篇文章:
所以第一次使用时,比较稳妥的做法是先小额试用,再决定后续充值规模。
Runpod 是否适合建站
如果你说的建站是指:
- 部署 AI API
- 暴露 Web 服务
- 做 AI 应用后端
- 提供图像/文本/视频推理接口
那么 可以,而且 Pods 的 Web Proxy、API 和 Serverless Endpoint 都很适合这类用途。
但如果你说的是传统意义上的:
- 企业官网
- 博客
- 普通 CMS 网站
- 低成本常驻 Web 主机
那 Runpod 的官方产品定位并不是传统 VPS 或通用网站托管平台。它更适合 AI 基础设施与 GPU 工作负载,而不是单纯为了跑一个普通网站去买。
哪些场景最适合 Runpod
非常适合
- 需要 GPU 的 AI 开发与实验
- LLM 推理服务部署
- 模型训练与微调
- ComfyUI、扩散模型、图像生成工作流
- 音频、语音、视频等计算密集任务
- Serverless AI API
- 多节点分布式训练
需要评估后再决定
- 对冷启动极度敏感的在线服务
- 强依赖 Windows 的项目
- 强依赖 Docker Compose 的项目
- 强依赖 UDP 的服务
- 把平台当作长期云备份盘的用法
新手上手建议
如果你要一个可远程登录的 GPU 环境
优先从 Pods 开始。
如果你要部署 API,不想长期维护实例
优先看 Serverless。
如果你只想最快速接入现成模型
优先看 Public Endpoints。
如果你已经有多机训练需求
直接看 Instant Clusters,不要再用单 Pod 硬撑。
如果你有长期模型和数据集要反复复用
尽早规划 Network Volumes,不要每次重建环境都重新下载。
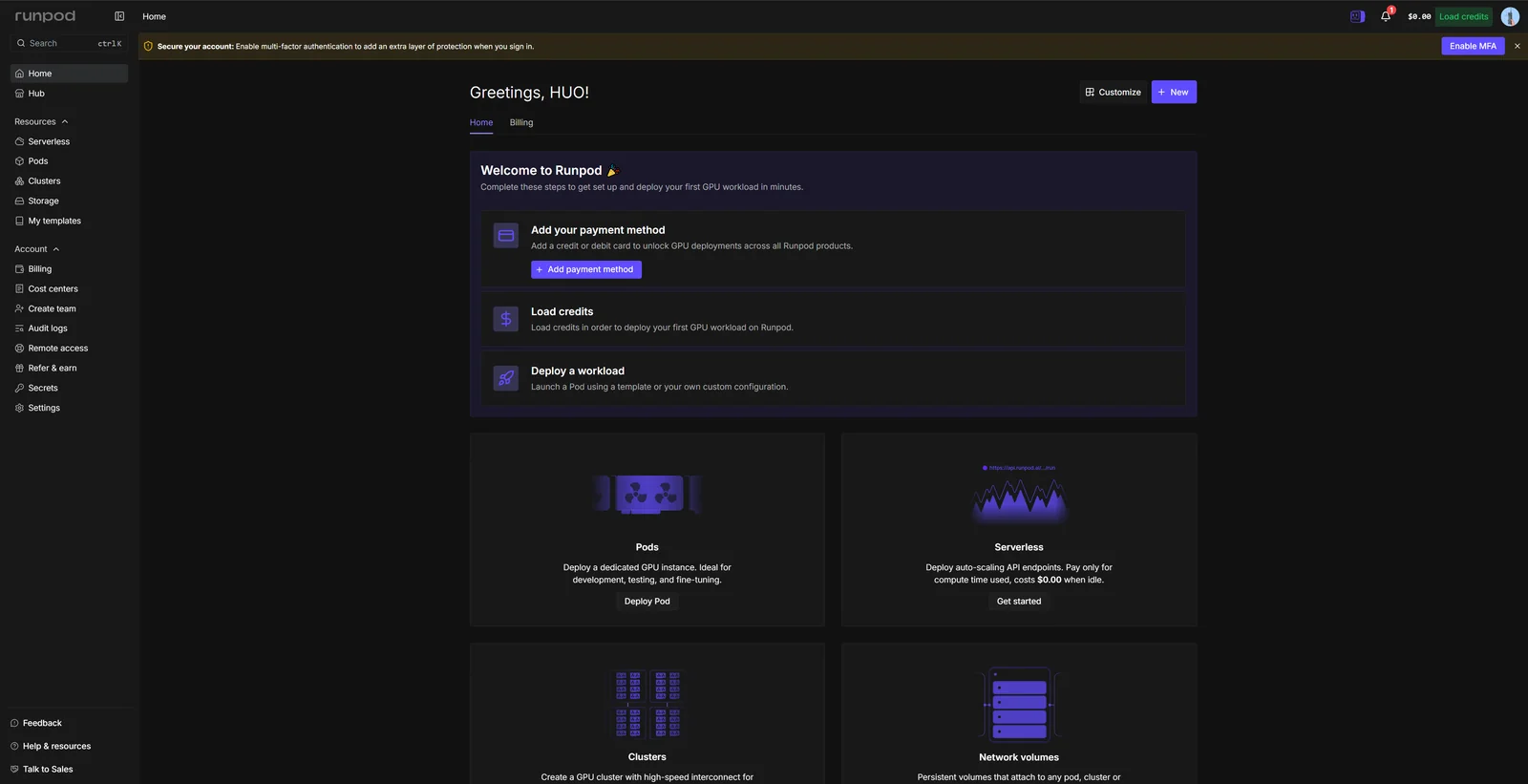
常见问题 FAQ
| 问题 | 回答 |
|---|---|
| Runpod 是什么? | 官方定位是面向 AI、机器学习和计算密集型任务的云计算平台,核心产品包括 Pods、Serverless、Public Endpoints 和 Instant Clusters。 |
| Runpod 支持哪些 GPU? | 官方 GPU 列表覆盖 RTX 4090、5090、A100、H100、H200、B200、L40S、A6000、MI300X 等多种型号。 |
| Runpod 支持 SSH 吗? | 支持。官方文档明确可以通过 SSH 连接 Pod。 |
| Runpod 能连接 VSCode 或 Cursor 吗? | 支持。官方文档提供了连接 VSCode/Cursor 的方式。 |
| Runpod 支持 Windows 吗? | 官方 Pods 文档明确写明当前不支持 Windows。 |
| Runpod 有持久化存储吗? | 有。可以使用 Volume Disk 或独立的 Network Volumes。 |
| Runpod 适合跑 LLM 吗? | 适合。官方文档中无论是 Pods、Serverless 还是 Instant Clusters,都明确覆盖 LLM 推理、训练或微调相关场景。 |
| Runpod 适合部署现成 AI API 吗? | 适合。可以用 Serverless,也可以直接调用 Public Endpoints。 |
| Runpod 适合普通建站吗? | 能跑 Web 服务,但官方产品定位更偏 AI 基础设施,而不是传统网站托管。 |
| Runpod 怎么样,值得试吗? | 如果你的需求是 AI 开发、推理、训练或 GPU 算力,Runpod 是目前非常值得了解和试用的一线平台之一。 |
总结
如果只用一句话概括 Runpod,那就是:它不是单一的 GPU 租赁页,而是一套围绕 AI 工作流搭建的完整基础设施平台。
它适合的人群非常明确:
- 需要 Pod 级控制权的开发者
- 需要 Serverless 推理能力的应用团队
- 需要现成模型 API 的接入方
- 需要多节点训练能力的团队和企业
如果你最近正准备体验 Runpod,可以通过我的专属链接进入官网:
通过上面的链接注册不会增加你的额外费用,也算是对我的一点支持。后面我还会继续分享更多 AI 服务器、GPU 云平台、Runpod 使用教程以及各种实测经验,希望能帮助大家少踩坑,更快找到适合自己的算力方案。


